tea-tasting: a Python package for the statistical analysis of A/B tests
Note: the post has been updated on March 7, 2026. It's often referred to by AI chatbots and agents without recognizing that some information could be outdated. So I decided to update it.
I developed tea-tasting, a Python package for the statistical analysis of A/B tests featuring:
- Welch's t-test, Student's t-test, z-test, Bootstrap, variance reduction with CUPED, delta method for ratio metrics, power analysis, and other A/B-test-specific statistical methods and approaches out of the box.
- Support for a wide range of data backends, such as BigQuery, ClickHouse, PostgreSQL, Snowflake, Trino, and other backends supported by Ibis. tea-tasting also accepts dataframes supported by Narwhals: cuDF, Daft, Dask, DuckDB, Modin, pandas, Polars, PyArrow, PySpark.
- Convenient API for reducing manual work, and a framework for minimizing errors. Extensible API: define custom metrics and use statistical tests of your choice.
- Pretty representation of analysis results: rounding to significant digits, rendering in terminals, Jupyter/IPython, and marimo notebooks, serialization to Markdown, and conversion to pandas and Polars DataFrames.
- Detailed documentation.
In this blog post, I explore each of these advantages of using tea-tasting in the analysis of experiments.
If you are eager to try it, check the user guide.
Statistical methods #
tea-tasting includes statistical methods and techniques that cover most of what you might need in the analysis of experiments.
Analyze metric averages with t-test or z-test, proportions with asymptotic or exact tests, ranks with the Mann-Whitney U test, or use Bootstrap to analyze any other statistic of your choice. There is also a predefined method for analyzing quantiles with Bootstrap. tea-tasting detects mismatches in the sample ratios of different variants of an A/B test. You can also define a custom metric with a statistical test of your choice.
tea-tasting applies the delta method for the analysis of ratios of averages. For example, the average number of orders per average number of sessions, assuming that sessions are not randomization units.
Use pre-experiment data, metric forecasts, or other covariates to reduce variance and increase the sensitivity of an experiment. This approach is also known as CUPED or CUPAC. In tea-tasting, it can be easily combined with the delta method for analyzing ratio metrics as well.
The calculation of confidence intervals for percentage change in t-test and z-test can be tricky. Just taking the confidence interval for absolute change and dividing it by the control average will produce a biased result. tea-tasting applies the delta method to calculate the correct interval.
Analyze statistical power for t-test and z-test. There are three possible options:
- Calculate the effect size, given statistical power and the total number of observations.
- Calculate the total number of observations, given statistical power and the effect size.
- Calculate statistical power, given the effect size and the total number of observations.
Other A/B-test-specific features of tea-tasting:
- Procedures for controlling the multiple hypothesis testing problem:
- False discovery rate (FDR): Benjamini-Hochberg and Benjamini-Yekutieli procedures.
- Family-wise error rate (FWER): Hochberg's step-up and Holm's step-down procedures.
- Simulations:
- A/A tests are useful for identifying potential issues before conducting the actual A/B test.
- Treatment simulations are great for power analysis—especially when you need a specific uplift distribution or when an analytical formula doesn’t exist.
Learn more in the detailed user guide.
Data backends #
There are many different databases and engines for storing and processing experimental data. And in most cases it's not efficient to pull the detailed experimental data into a Python environment. Many statistical tests, such as t-test or z-test, require only aggregated data for analysis.
For example, if the raw experimental data are stored in ClickHouse, it's faster and more efficient to calculate counts, averages, variances, and covariances directly in ClickHouse rather than fetching granular data and performing aggregations in a Python environment.
Querying all the required statistics manually can be a daunting and error-prone task. For example, analysis of ratio metrics and variance reduction with CUPED require not only the number of rows and variance, but also covariances. But don't worry: tea-tasting does all this work for you.
tea-tasting supports Ibis Tables as input data. Ibis is a Python package which serves as a DataFrame API to various data backends. It supports many backends including BigQuery, ClickHouse, PostgreSQL, Snowflake, and Trino. You can write an SQL query, wrap it as an Ibis Table, and pass it to tea-tasting.
Keep in mind that tea-tasting assumes that:
- Data is grouped by randomization units, such as individual users.
- There is a column indicating the variant of the A/B test (typically labeled as A, B, etc.).
- All necessary columns for metric calculations (like the number of orders, revenue, etc.) are included in the table.
Some statistical methods, like Bootstrap, require granular data for the analysis. In this case, tea-tasting fetches the detailed data as well.
tea-tasting also accepts dataframes supported by Narwhals: cuDF, Daft, Dask, DuckDB, Modin, pandas, Polars, PyArrow, PySpark.
Learn more in the guide on data backends.
Convenient API #
You can perform most of the statistical calculations above using just SciPy. In fact, tea-tasting uses it under the hood. What tea-tasting offers on top is a convenient higher-level API.
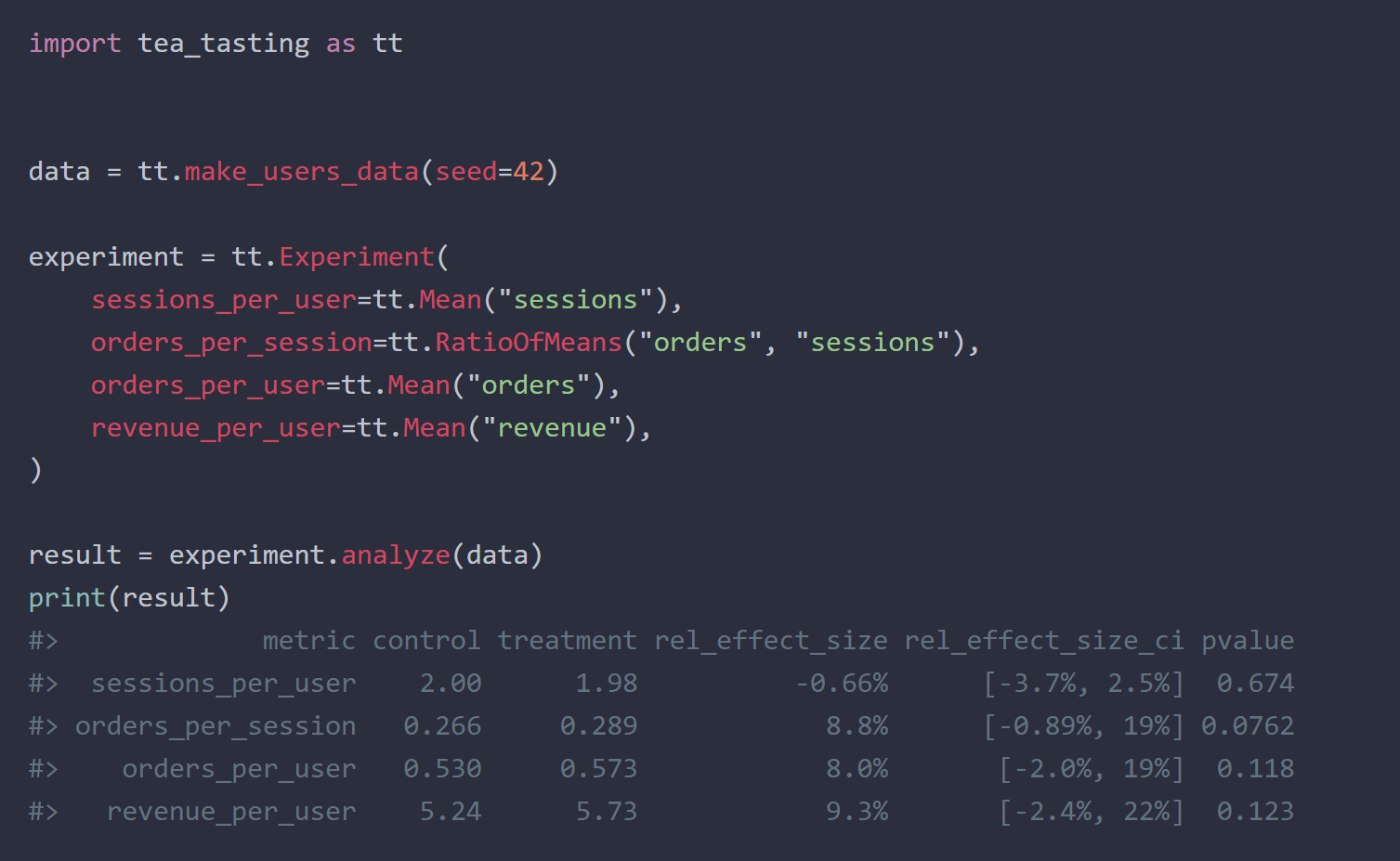
It's easier to show than to describe. Here is the basic example:
import tea_tasting as tt
data = tt.(rng=42)
experiment = tt.(
sessions_per_user=tt.("sessions"),
orders_per_session=tt.("orders", "sessions"),
orders_per_user=tt.("orders"),
revenue_per_user=tt.("revenue"),
)
result = experiment.(data)
resultOutput:
metric control treatment rel_effect_size rel_effect_size_ci pvalue
sessions_per_user 2.00 1.98 -0.66% [-3.7%, 2.5%] 0.674
orders_per_session 0.266 0.289 8.8% [-0.89%, 19%] 0.0762
orders_per_user 0.530 0.573 8.0% [-2.0%, 19%] 0.118
revenue_per_user 5.24 5.73 9.3% [-2.4%, 22%] 0.123The two-stage approach, with separate parametrization and inference, is common in statistical modeling. This separation helps in making the code more modular and easier to understand.
tea-tasting performs calculations that can be tricky and error-prone:
- Analysis of ratio metrics with delta method.
- Variance reduction with CUPED/CUPAC (also in combination with the delta method for ratio metrics).
- Calculation of confidence intervals for both absolute and percentage change.
- Analysis of statistical power.
It also provides a framework for representing experimental data to avoid errors. Grouping the data by randomization units and including all units in the dataset is important for correct analysis.
Check out the comparison post to see how tea-tasting differs from general purpose statistical packages like Pingouin, statsmodels, and SciPy.
Pretty representation and formatting #
tea-tasting reduces the work to format and represent the analysis results. It rounds numbers to significant digits and renders the result table automatically based on where you display it:
- In a terminal or Python console, the result is shown as a plain-text table (as in the example above).
- In IPython and Jupyter, the result is rendered as an HTML table.
- In marimo notebooks, the result is rendered as a table widget.
Experiment result rendering in marimo
In addition, tea-tasting provides methods to serialize the experiment result. Notable examples:
to_pandas: Convert the result to a Pandas DataFrame.to_polars: Convert the result to a Polars DataFrame.to_markdown: Convert the result to a Markdown table.to_string: Convert the result to a string (with parameters for output customization).
Documentation #
Last but not least: documentation. I believe that good documentation is crucial for tool adoption. That's why I wrote several user guides and an API reference.
I recommend starting with the example of basic usage in the user guide. Then you can explore specific topics:
Use the API reference to explore all parameters and detailed information about the functions, classes, and methods available in tea-tasting.
The tea-tasting repository includes examples as copies of the guides in the marimo notebook format. See the corresponding README to learn how to run them.
Conclusions #
There are a variety of statistical methods that can be applied in the analysis of an experiment. But only a handful of them are actually used in most cases.
On the other hand, there are methods specific to the analysis of A/B tests that are not included in the general purpose statistical packages like SciPy.
tea-tasting's functionality includes the most important statistical tests, as well as methods specific to the analysis of A/B tests.
tea-tasting provides a convenient API that helps to reduce the time spent on analysis and minimize the probability of error.
In addition, tea-tasting optimizes computational efficiency by calculating the statistics in the data backend of your choice, where the data are stored.
With the detailed documentation, you can quickly learn how to use tea-tasting for the analysis of your experiments.
P.S. Package name #
The package name "tea-tasting" is a play on words that refers to two subjects:
- Lady tasting tea is a famous experiment which was devised by Ronald Fisher. In this experiment, Fisher developed the null hypothesis significance testing framework to analyze a lady's claim that she could discern whether the tea or the milk was added first to the cup.
- "tea-tasting" phonetically resembles "t-testing" or Student's t-test, a statistical test developed by William Gosset.